介绍(Introduction)
Web 浏览器很可能是使用最广泛的应用软件。在这本书里,我将解释其底层是如何工作的。当你在浏览器地址栏里输入 “google.com” ,直到在浏览器里展示出谷歌网页使,我们将清楚浏览器是如何实现的。
关于浏览器(The browsers we will talk about)
目前主要有5种使用较广泛的浏览器:Internet Explorer, Firefox, Safari, Chrome and Opera。
我将提供一些来自于 Firefox、Chrome 和 Safari 中的部分源码示例。
根据 W3C 对浏览器使用情况的统计(2009),使用 Firefox、Safari 和 Chrome 共占比接近 60%。
因此,目前开源浏览器在整个浏览器市场中是重要的组成部分。
浏览器主要功能(The browser’s main functionality)
浏览器主要功能就是把你选择的存在的 web 资源,通过请求从服务器展现到浏览器窗口。资源的格式通常为HTML,但也包括 PDF、图片等。资源的地址由使用者使用 URI 地址指定。更多详情参加相关网络章节。
浏览器解析和展现 HTML 文件的方法在 HTML 和 CSS 规范有详细说明。哪些规范由 W3C(Word Wide Web Consortium)组织维护,它是 web 的官方组织。
HTML 最新版本是 4。版本 5 正在制定中。CSS 最新版本是 2,版本 3 正在制定中。
多年来各浏览器只遵从一部分规范,然后开发他们自己的扩展功能,这为 web 开发者导致了严重的兼容性问题。今天大多数浏览器或多或少遵从了规范。
各浏览器的用户界面彼此之间有很多相似点,常见的用户界面元素有如下几种:
- 用于填写 URI 的地址栏
- 后退和前进的按钮
- 书签选项
- 一个刷新按钮提供更新功能,一个停止按钮为正在加载中的文档提供停止更新功能
- 首页按钮提供回到首页功能
奇怪的是,浏览器的用户界面没有任何正式的规范来详细说明,它仅仅是过去几年最佳实践的经验以及浏览器间相互模仿造成的。HTML5 规范没有定义一个浏览器必须具备哪些 UI 元素,但列出了一些公共的元素。地址栏、状态栏和工具栏这些位列其中。当然,还有某些浏览的独有功能,例如 Firefox 的下载管理器。更多详情参见用户界面章节。
浏览器的高级结构(The browser’s high level structure)
浏览器有以下主要组成部分:
- 用户界面 - 它包括了地址栏、后退/前进按钮、书签菜单等。除了用来展示网页的主窗口以为,其余没一部分都会展示出来。
- 浏览器引擎 - 用于查询和操作渲染引擎的接口。
- 渲染引擎 - 负责显示指定的内容。例如,如果要求显示的内容是 HTML,它就负责解析 HTML 和 CSS 并且在屏幕上显示出解析出的内容。
- 网络 - 用于网络呼叫,例如:HTTP 请求。它有独立于平台的接口和每个平台的底层实现。
- UI 后端 - 用于绘制基础部件,例如:组合框和窗口。它暴露出未特定平台的通用接口。底层实现使用了操作系统的用户界面方法。
- JavaScript 解释器 - 用于解析和执行 JavaScript 代码
- 数据存储 - 这是一个持久性层。浏览器需要再硬盘上保存所有类型的数据,例如:cookies。新 HTML 规范(HTML5)定义的 “web database”在浏览器中是完整(虽然是轻量的)的数据库。

Figure 1:Browser main components.
值得注意的是,Chrome 不同于大多数浏览器,它的渲染引擎拥有多实例 - 每个页签对应一个实例。每个页签拥有一个自己的进程。
我将把以上每个部分都用一个章节来详细讲解。
各组成部分之间的联系(Communication between the components)
Firefox 和 Chrome 都开发有特定通信设施。它们将在一个特别的章节进行讲解
渲染引擎(The rendering engine)
渲染引擎的职责是渲染,就是在浏览器屏幕上呈现出指定的内容。
渲染引擎默认能呈现 HTML 和 XML 文档,以及图片。通过一个 plug-in(浏览器扩展)也能呈现其他类型。例如:PDF 使用一个 PDF 查看器扩展就能呈现。我们在一个特别的章节讨论这些插件和扩展。在这一章节我们集中在主要使用的部分——呈现使用 CSS 格式化过的 HTML 和 图片。
渲染引擎(Rendering engines)
我们提到的浏览器:Firefox、Chrome 和 Safari 都建立在两个渲染引擎之上,Firefox 使用了 Gecko(一个“自制”的 Mozilla 渲染引擎)。Safari 和 Chrome 使用了 Webkit。
Webkit 是一个开源渲染引擎,它最初是 Linux 平台的一个引擎,后来被 Apple 修改为支持 Mac 和 Windows。在 https://webkit.org/ 可以看到更多详情。
主要流程(The main flow)
渲染引擎从网络层获取到指定文档的内容时开始工作。这通常在8K的块(每次从网络层中获取的内容)中完成。
之后渲染引擎处理的主要流程如下:
 <br />**Figure 2:Rendering engine basic flow.**<br />**<br />渲染引擎将以解析 HTML 文档和把标签转换为树(content tree)中的 DOM 节点开始,将解析样式数据,包含外部 CSS 文件和内联样式。样式信息与 HTML 中的视觉指令将被用来生成另一种树 - 渲染树。<br />渲染树包含了一个个带有视觉属性,类似颜色和尺寸的长方形盒子。这些长方形盒子被有序地呈现在屏幕上。<br />渲染树构造好之后,将通过一个布局(layout)的过程。这意味着将给每个节点一个在屏幕上出现的真实的坐标。下一阶段就是绘制(painting)- 渲染树将被遍历以及每个节点都将使用 **UI 后端层**进行绘制。<br />
重要的是要理解这是一个渐进的过程(gradual process)。为了更好的用户体验,渲染引擎会尝试尽快地在屏幕上呈现出内容。它不会等到所有HTML都被解析之后才开始构建和布局渲染树。内容的一部分在解析和呈现,同时也在持续接受网络层传来的剩余内容。
**
主要流程示例(Main flow examples)

Figure 3: Webkit main flow
Figure 4: Mozilla’s Gecko rendering engine main flow
从图3和图4可以看出,Webkit 和 Gecko 使用了略微不同的术语,流程本质上还是一致的。
Gecko 把格式化后视觉元素的树称为框架树(Frame tree)。每个元素就是一个框架(Frame)。Webkit 则用术语渲染树(Render Tree)和其组成部分渲染对象(Render Objects)来表示。Webkit 使用术语布局(Layout)表示元素的位置,Gecko 则称为回流(Reflow)。连接器(Attachment)是 Webkit 用来连接DOM节点和可视化信息来创建渲染树的术语。一个较小的非语义的差异就是 Gecko 在 HTML 和 DOM tree 之间额外多了一层,称为内容槽(content sink),是一个标记 DOM 元素的工厂。下面将讨论流程汇总的每一个部分:
**
解析和 DOM 树结构(Parsing and DOM tree construction)
常规解析(Parsing - general)
由于解析在渲染引擎中是一个非常重要的过程,因此我们将走得更深入一点。让我们开始简短的介绍下解析部分(paring)。
解析一个文档意味着将其翻译成一些有意义的结构 - 一些代码能够理解和使用。解析的结果通常是一个表示文档结构的结点树。我们称为解析树或者语法树。
例如:解析表达式“2 + 3 - 1”能返回这个树:
Figure 5: mathematical expression tree node
Grammars
解析基于文档遵守的语法规则(书写的语言或格式)。每种格式都必须解析出由词汇表和语法规则组成的确定性的语法。这被称为上下文无关语法(context free grammar)。人类语言不是这类语言,因此无法传统的解析技术进行解析。
(解析器 - 结合词法分析器)Parser - lexer combination
解析可以被分为两个子流程:词法分析(lexical analysis)和语法分析(syntax analysis)。
词法分析是将输入拆分为词(token)的过程。词就是语言中的词汇表(有效构造块的集合)。在人类语言中,就是该语言在词典中出现的所有单词组成的。
语法分析是语言语法规则的应用。
解析器通常分为两部分:负责将输入拆分为有效词汇的词法分析器(lexer)或分词器(tokenizer),以及负责遵循语言规则分析出文档结构,进而构造出解析树(parse tree)的解析器。词法分析器知道如何去除无关紧要的符号,例如:空格和换行符。
Figure 6: from source document to parse trees
**
解析过程是迭代的,解析器通常向词法分析器请求新的词(token),然后尝试匹配一条语法规则,如果与一条规则匹配,与之对应的结点将被添加到解析树中,然后将继续请求另一个词(token)。
如果没有匹配到规则,解析器将在内部存储这个词(token),然后继续请求词(token)直到找到匹配内部存储的所有词的规则。如果没有找到规则,那么解析器将引发一个异常,这意味着该文档无效并且包含有语法错误。
翻译(Translation)
多数时候解析树不是最终产品,翻译中常使用解析 - 将输入文本翻译为另一种格式。例如汇编。把源码编译成机器码的编译程序首先将其解析成解析树,然后翻译把解析树翻译成机器码文档。
Figure 7: compilation flow
解析示例(Parsing example)
图5中,我们构建了一个数学表达式的解析树,让我们尝试定义一个简单的数学语言来看看解析流程。
词汇表:我们的语言包括整数、加号和减号。
语法:
1. 该语言语法构建块是表达式、术语和操作
1. 该语言能包括任意数量的表达式
1. 表达式(expression)定义为一个术语(term)后面跟着一个操作(operation),再跟着另一个术语(term)
1. 操作(operation)是指加号(plus token)或者减号(minus token)
1. 术语是指一个整数(integer)或者一个表达式(expression)让我们解析输入“2 + 3 - 1”。
第一个子串匹配到规则的是“2”,根据规则#5,它是一个术语。第二次匹配是“2 + 3”匹配到规则#2 - 一个术语后跟着一个操作再跟着另一个术语。下一次匹配将只会在输入的末尾被命中。“2 + 3 - 1”是一个表达式因为我们已经知道“2 + 3”是一个术语,因此我们拥有了一个术语后跟着一个操作再跟着另一个术语。“2 + +”将不能匹配任何规则因此是无效的输入。
正式定义词汇和语法(Formal definitions for vocabulary and syntax)
词汇表通常由正则表达式(regular expressions)表示。
例如我们的语言将被定义为:
INTEGER:0|[1-9][0-9]*
PLUS: +
MINUS: -
正如你所看到的,整数被定义为一个正则表达式。
语法通常被定义为一种 BNF(Backus–Naur form) 格式。我们的语言将被定义为:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
我们说一种语言如果它的语法是无上下文语法,则能通过常规解析器被解析。无上下文语法可简单定义为语法能完全用 BNF 格式表示。正式的定义参加http://en.wikipedia.org/wiki/Context-free_grammar
解析器的类型(Types of parsers)
解析器有两个基本类型 - 自上而下解析器(top down parsers)和自下而上解析器(bottom up parsers)。自上而下解析器可简单定义为解析器查看语法的高级结构,并尝试匹配其中的一个。自下而上解析器从输入开始,逐步转换为语法规则,从低级规则开始,直到能匹配高级语法为止。
来看看这两种解析器如何解析我们的示例:
自上而下解析器从最高级规则开始,它将定义“2 + 3”是一个表达式。然后定义“2 + 3 - 1”是一个表达式(定义表达式的过程会逐步匹配其他规则,但起点是最高级规则)。
自下而上解析器将浏览输入直到与一个规则匹配,然后用该规则替换匹配的输入。这个过程将持续到输入的结束。部分匹配出的表达式放在了解析栈上。
| Stack | Input |
|---|---|
| 2 + 3 - 1 | |
| term | 2 + 3 - 1 |
| term operation | 3 - 1 |
| expression | -1 |
| expression operation | 1 |
| expression |
这种自下而上解析器被称为渐变减少解析器(shif reduce parser),因为输入被向右平移(想象下指针从输入的开始向右移动)并逐步简化为语法规则。
自动生产的解析器(Generation parsers automatically)
有些工具能为你生成解析器。它们被称为解析生成器。你提供语言的语法给它们 - 词汇表和语法规则,然后就生成一个能工作的解析器。创建一个解析器需要深入理解解析原理并且不容易手动创建出优化的解析器,因此解析生成器非常有用。
Webkit 使用了两个非常好的解析生成器 - 创建词法分析程序的Flex和创建解析器的Bison(你可能会遇到它们的名称是Lex 和 Yacc)。Flex 的输入是一个包含用正则表达式定义词(token)的文件。Bison 的输入是用 BNF 格式表示的语言语法。
HTML 解析器(HTML Parser)
HTML 解析器的工作是把 HTML 标记解析成解析树。
HTML 语法定义(The HTML grammer definition)
HTML 的词汇表和语法规范由 W3C 组织创建。现在的版本是HTML4,HTML5正在制定中。
不是上下文无关语法(Not a context free grammer)
正如我们在解析器介绍中看到,语法的语法能使用 BNF 等格式进行正式定义。
不幸的是所有传统的解析器主题都不适用于 HTML (我提到它们不是为了好玩,它们将被用于 CSS 解析和 JavaScript 解析)。HTML 不能简单地由解析器需要的上下文无关语法进行定义。
DTD(Document Type Definition)是一个定义 HTML 的正式格式,但不是一个上下文无关语法。
这在第一个站点上看起来很奇怪——HTML 非常接近 XML,有许多可用的 XML 的解析器。HTML-XHTML是一个 XML 的变体,因此它们最大区别是什么呢?
区别就是 HTML 更“宽容”,它默默地加上你疏忽掉特定的标记,有时省略开始或结束标记等。总的来说,它是一种“软”语法,与 XML 的硬和苛刻的语法相反。
很明显,这个看起来很微小的不同使得世界变得不同。一方面这是 HTML 如此流行的主要原因——它忽略你的错误,使得 web 作者的生活更容易;另一方面,它使得语法格式很难写。总结下——HTML 不容易被解析,自从它的语法不是上下文无关语法开始,既不适用于传统解析器,也不适用于 XML 解析器。
HTML DTD
HTML定义在一个 DTD 格式里。这种格式被用于定义 SGML 家族语言。这种格式包含所有元素及其属性和层次结构的定义。正如我们前面看到的,HTML DTD 不是上下文无关语法。
DTD 有几种变体。严格模式严格遵守规范,但其他几种模式包含对浏览器对过去使用的标记的支持。目的是向后兼容旧的内容。现在的严格 DTD 地址:http://www.w3.org/TR/html4/strict.dtd
DOM
输出的树——解析树是 DOM 元素和属性的节点组成的树。DOM是 Document Object Model 的简称。它是 HTML 文档的对象表示和 HTML 元素与外部世界(如 JavaScript)的接口。
这个树的根节点是 Document 对象。
DOM 与标记几乎是一对一的关系。例如,这些标记:
1 | <html> |
将被翻译为下面这样的DOM树:
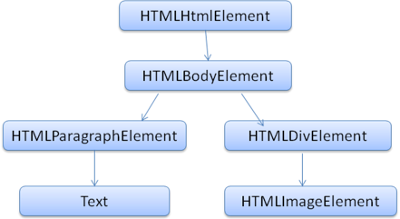<br />**Figure 8: DOM tree of the example markup**如何 HTML,DOM 也由 W3C 组织具体说明,可见:https://www.w3.org/DOM/DOMTR。这是一个操作文档的通用规范。特定的模块描述 HTML 特定元素。HTML 规范可在这里找到:https://www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html。
当我看说树中包含了 DOM 节点,我的意思是树由某个 DOM 接口的元素构建的。浏览器使用浏览器内部具有其它属性的具体实现。
解析算法(The parsing algorithm)
正如在前面几节中看到的,HTML 不能被通常的自上而下的解析器解析。
原因如下:
1. 语言的宽容本性
1. 浏览器需要具有传统的错误容忍度,以支持已知的无效HTML的事实。
1. 解析过程可重入(可重入(**Reentrant**):函数可以由多于一个线程并发使用,而不必担心数据错误。可重入函数可以在任意时刻被中断,稍后再继续运行,不会丢失数据。)。通常资源在解析过程中不会改变,但在 HTML 中,包含“document.write”的 script 标签能添加额外的词(tokens),因此解析过程实际上会修改输入。由于不能使用常规解析器技术,浏览器为解析 HTML 创建了自定义的解析器。
这个解析算法描述的是 HTML5 规范的细节。这个算法由标记(tokenization)和构建树两个阶段组成。
标记是把输入通过词法分析、解析转变成标记(tokens)。HTML 标记包含开始标记、结束标记、属性名称和属性值。
分词器识别出标记,将其交给构建树,然后使用下一个字符识别出下一个标记,以此类推,直到输入结束。
Figure 6:HTML parsing flow(taken from HTML5 spec)
标记算法(The tokenization algorithem)
该算法输入一个 HTML 词,该算法用状态机(state machine)表示。每个状态消耗输入流的一个或多个字符,并且根据那些字符更新到下一个状态。该决策收到当前标记化状态和树构造状态的影响。这意味着根据当前的状态,消耗同一个字符将为正确的下一个状态产出不同的结果。该算法太复杂而不能完全引入,因此让我们通过一个简单的示例帮助我们理解原理。
基础示例 - 标记下面的 HTML:
1 | <html> |
初始状态是“Data state”,当遇到字符“<”时,状态将被改变为“Tag open state”。继续消耗一个“a-z”的字符会创建一个“Start tag token”(开始标记),状态变为“Tag name state”。一直保持在这个状态直到字符“>”被消耗。每个字符都会附件到新的标记名称上。在我们的例子中,创建的标记是一个 “html”标记。
当“>”标签到达是,当前标记被发出并且状态变回到“Data state”。“body” 标签将被相同的步骤处理。到目前为止,“html”和“body”都已发出。现在回到“Data state”状态。消费“Hello world”中的“H”将创建并发出一个字符标记,一直持续到“”中的“<”到达。这期间我们发出了“Hello world”中每一个字符的标记。现在我们回到“Tag open state”状态。继续消费下一个输入“/”将创建一个“end tag token”(结束标记)并且移动到“Tag name state”状态。再一次保持这个状态知道“>”到来。然后一个新标签标记将被发出,且回到“Data state”状态。输入的“”将像之前的例子一样被处理。
Figure 9: Tokenizing the example input
**
构造树算法(Tree construction algorithm)
当解析器被创建时,文档对象也被创建。在树构造阶段,将修改文档根目录中的 DOM 树,并向其添加元素。分词器发出的每个节点都将由树构造处理。每个标记都有 DOM 元素的规范定义与之对应并为其构建。除非添加到DOM 树的元素也添加开放元素的堆栈中了。这个栈被用于纠正嵌套不匹配和未关闭的标签。该算法也描述为一个状态机。这些状态被称为插入模式(insertion modes)。
让我们来看看实例输入的树构造过程:
1 | <html> |
树构造阶段输入是一系列来自标记阶段的标记,第一个模式是初始模式(initial mode)。接收到这个html 标记将导致切换到“before html”模式并且在该模式下对标记重新处理。这将导致HTMLHtmlElement 元素诞生并且它将被添加到文档对象(Document Object)的根节点。
状态将切换到“before head”。我们接收到“body”标记,尽管我们没有“head”标记,HTMLHeadElement 元素仍会被隐含的创建并添加到树中。
现在我们切换到“in head”模式,然后切换到“after head”。这个 body 标记被重新加工,HTMLBodyELement 被创建并插入,且模式转换为“in body”。
“Hello world” 字符串的字符标记现在被接收到,第一个标记将导致一个“Text”节点被创建和插入,其他字符将被添加到这个节点上。
接收到body的结束标记将导致转换到“after body”模式。我们将接收到html 结束标签将切换到“after after body”模式。接收到文件结束的标记将结束解析。
Figure 10: tree construction of example html
解析完成之后的行为(Actions when then parsing is finished)
解析完成之后浏览器将文档标记为交互式的,并开始解析“deferred”模式中的脚本(scripts)——哪些应该在文档被解析之后被运行。文档状态之后将被设置为“complete”,且“load”事件将被激活。
你将在HTML5 规范中看到标记、书构造的完整算法。
浏览器容错处理(Browsers error tolerance)
你绝不会在一个HTML页面获取到“Invalid Syntax”错误。浏览器将修复无效的内容,然后继续。拿这段HTML举例:
1 | <html> |
我必须违反上百万的规则(“mytag”不是标准标签,“p”的“div”错误嵌套),但浏览器仍然正确的展示并且没有提出抗议。因此很多解析代码都是为了修复HTML作者的错误。
在不同浏览器中,错误处理非常一致,但令人惊讶的是它不是HTML当前规范的一部分。就像书签和后退/前进按钮,它只是多年来浏览器开发出来的东西。他们知道在很多站点重复出现无效的HTML结构,然后和其它浏览器以一种符合要求的方式尝试去修复它们。
HTML5 规范确实定义其中一些需求。Webkit 在HTML 解析类开头的注释中很好的总结这一点。
这个解析器把标记化的输入解析到文档中,创建出文档树。如果这个文档格式良好,就直接地解析它。
不幸的是,我们必须处理很多那些格式不够良好的文档,因此解析器必须能够容忍错误。
我们必须至少关心下面几种错误情形:
- 正添加到某些外部标签的元素是被显示禁止的。这种情况,我们应该关闭被禁止元素之前的所有标签,然后将元素添加其后。
- 我们不允许直接地添加元素。可能写文档的人忘记了中间的某些标签(或其中的标签是可选的)。这可能是以下标签的情况:HTML HEAD BODY TR TD LI (我还忘记了哪些?)
- 我们想添加块级元素到一个行级元素中。关闭所有行级元素直到下一个更高级的块元素。
- 如果这没有用,关闭元素直到允许被添加的元素或者忽略这个标签。
让我们看一些Webkit 容错处理的例子:
替代
一些网站使用
替代
。为了被IE兼容,FIrefox Webkit 如此处理像
等标签。
1 | if (t->isCloseTag(brTag) && m_document->inCompatMode()) { |
注意——这个错误处理是内部的——它不会提供给用户。
- 走失的表格(a stray table)
走失的表格是指一个表格放在了另一个表格中,但确没有放在单元格中,举例如下:
1 | <table> |
Webkit 将修改这个结构变成两个兄弟表格:
1 | <table> |
代码如下:
1 | if (m_inStrayTableContent && localName == tableTag) |
Webkit 使用一个栈来保存当前元素内容——它将把里面的table从外部table栈中弹出。两个table之后便是兄弟关系了
- 嵌套的表单元素(Nested form elements)
这种情况是指用户将一个form 放入另一个form 中,第二个form 会被忽略。代码如下:
1 | if (!m_currentFormElement) { |
- 太深的标签层次结构(A too deep tag hierarchy)
这个注释不言自明。
www.liceo.edu.mx 这个站点就是一个例子,它达到了 1500个标记的嵌套级别,全部来自遗传 。我们仅允许大约 20 个相同类型的嵌套标签,然后将它们全部忽略。
1 | bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName) |
- 错误放置的html或body的结束标签(Misplaced html or body end tags)
同样,也有相应的注释说明。为支持不完整的html
我们从不关闭body标签,除非一些愚蠢的web页面在文档实际结束之前关闭它。我们依靠 end() 的调用来关闭这些东西。
1 | if (t->tagName == htmlTag || t->tagName == bodyTag ) |
因此 web 作者要小心——除非你想在Webkit 容错处理的代码中作为实例出现——编写格式良好的HTML。
CSS 解析(CSS parsing)
还记得介绍中的解析概念么?哦,这不像 HTML,CSS 是一个上下文无关的语法,也能使用介绍中的那类解析器来解析。事实上,CSS 规范定义了 CSS 词汇和语法(http://www.w3.org/TR/CSS2/grammar.html)。
让我们来看一些实例:
词汇语法(词汇)通过正则表达式定义了每一个词:
1 | comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/ |
语法使用 BNF 描述
- *****: 0 or more
- +: 1 or more
- ?: 0 or 1
- |: separates alternatives
- [ ]: grouping
1 | ruleset |
说明:ruleset 是下面这样的结构:
1 | div.error, a.error { |
div.error 和 a.error 都是 selector。在花括号中的部分包含通过这个 ruleset 应用的规则。它的结构被正式定义在这个描述中:
1 | ruleset |
这意味着一个 ruleset 是一个 selector 或者由逗号和空格分割的多个 selector(S 代表空格)组成。一个 ruleset 包含一对花括号且花括号中间是一个 declaration 或者由分号分割的多个 declaration。”declaration” 和 “selector” 将被定义在接下来的 BNF 定义中。
Webkit CSS 解析器(Webkit CSS parser)
Webkit 使用 Flex and Bison 生成器根据 CSS 语法文件自动创建解析器,正如你从解析器介绍中回想起的一样,Bison 创建一个自下而上的渐变减少解析器(shif reduce parser)。Firefox 使用手动编写的自上而下的解析器。两种情况都会把每个 CSS 文件解析成一个样式表对象(StyleSheet Object),每个对象包括了 CSS 规则。CSS 规则又包含了选择器(selector)、声明对象(declaration objects)以及其他 CSS 语法相关的对象。
Figure 7:parsing CSS
**
脚本解析(Parsing scripts)
这部分将在 JavaScript 章节处理。
处理脚本和样式表的顺序(The order of processing scripts and style sheets)
脚本(Scripts)
web 的模型是同步的。作者期望当解析到